Deep learning on point clouds has received increased attention thanks to its wide applications in AR/VR and autonomous driving. These applications require low latency and high accuracy to provide real-time user experience and ensure user safety. Unlike conventional dense workloads, the sparse and irregular nature of point clouds poses severe challenges to running sparse CNNs efficiently on the general-purpose hardware. Furthermore, existing sparse acceleration techniques for 2D images do not translate to 3D point clouds. In this paper, we introduce TorchSparse, a high-performance point cloud inference engine that accelerates the sparse convolution computation on GPUs. TorchSparse directly optimizes the two bottlenecks of sparse convolution: irregular computation and data movement. It applies adaptive matrix multiplication grouping to trade computation for better regularity, achieving 1.4-1.5x speedup for matrix multiplication. It also optimizes the data movement by adopting vectorized, quantized and fused locality-aware memory access, reducing the memory movement cost by 2.7x. We further introduce TorchSparse++, a new GPU library that takes advantage of pipelining and autotuning to design efficient computation to greatly improve the efficiency of TorchSparse. We create a highly efficient Sparse Kernel Generator that generates performant sparse point cloud convolution kernels at less than one-tenth of the engineering cost of the current state-of-the-art system. On top of this, we design the Sparse Autotuner, which extends the design space of existing point cloud libraries and searches for the best dataflow configurations for training and inference workloads. Consequently, TorchSparse++ achieves 2.9x, 3.3x, 2.2x and 1.7x measured end-to-end speedup on an NVIDIA A100 GPU over state-of-the-art MinkowskiEngine, SpConv 1.2, TorchSparse and SpConv v2 in inference; and is 1.2-1.3x faster than SpConv v2 in mixed precision training.

TorchSparse (MLSys 2022): [Paper] [Slides] [Video] [Code]
TorchSparse++ (MICRO 2023): [Project Page] [Paper] [Slides] [Poster] [Code] [Video (Coming Soon)]
Sparse convolution plays a crucial role in a variety of cutting-edge applications, including augmented/virtual reality (AR/VR), autonomous driving, and recommendation systems.

In contrast to dense convolution, sparse convolution strategically bypasses both computation and storage when processing zero activations. This capability empowers it to efficiently manage input scenes with significantly larger spatial resolutions, yet it also introduces challenges in terms of system optimization.
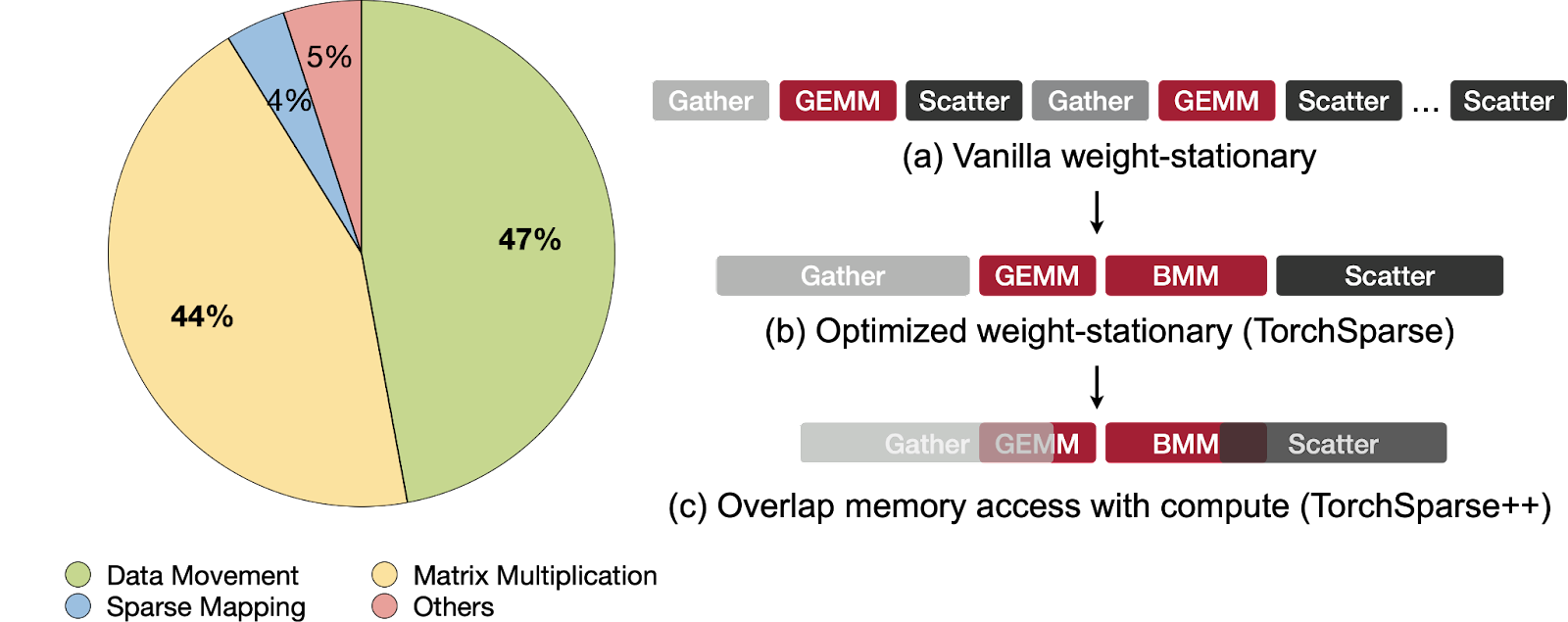
It is evident that both the computation of matrix multiplication and the management of data movement incur significant costs in sparse convolution. In TorchSparse (MLSys 2022) and its successor, TorchSparse++ (MICRO 2023), we have adopted distinct strategies to enhance the efficiency of sparse convolution.
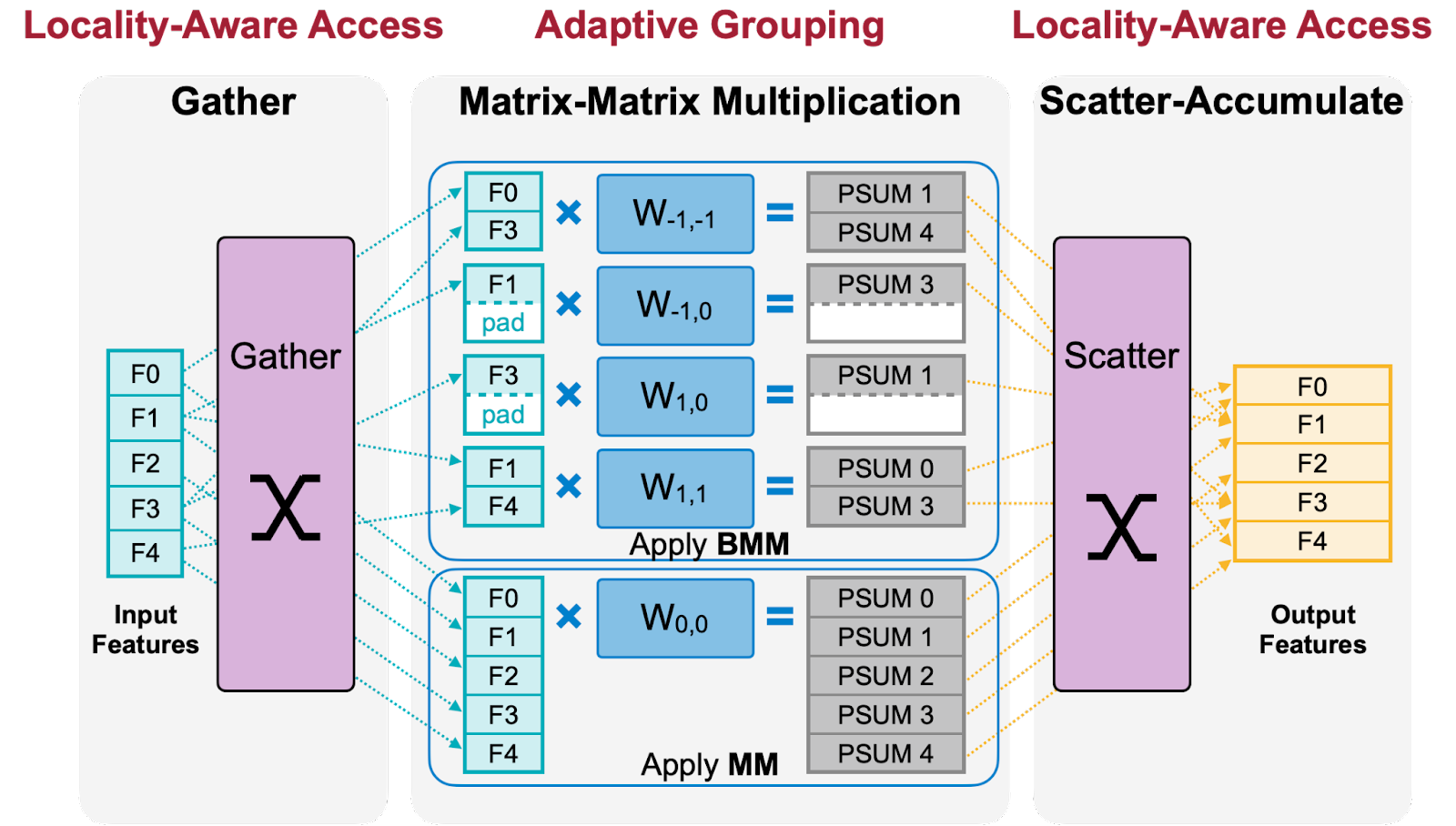
In TorchSparse, our primary innovation lies in the separate acceleration of matrix multiplication and data movement operations. We achieve this through the introduction of adaptive grouping to enhance device utilization and the adoption of locality-aware access to optimize cache efficiency.
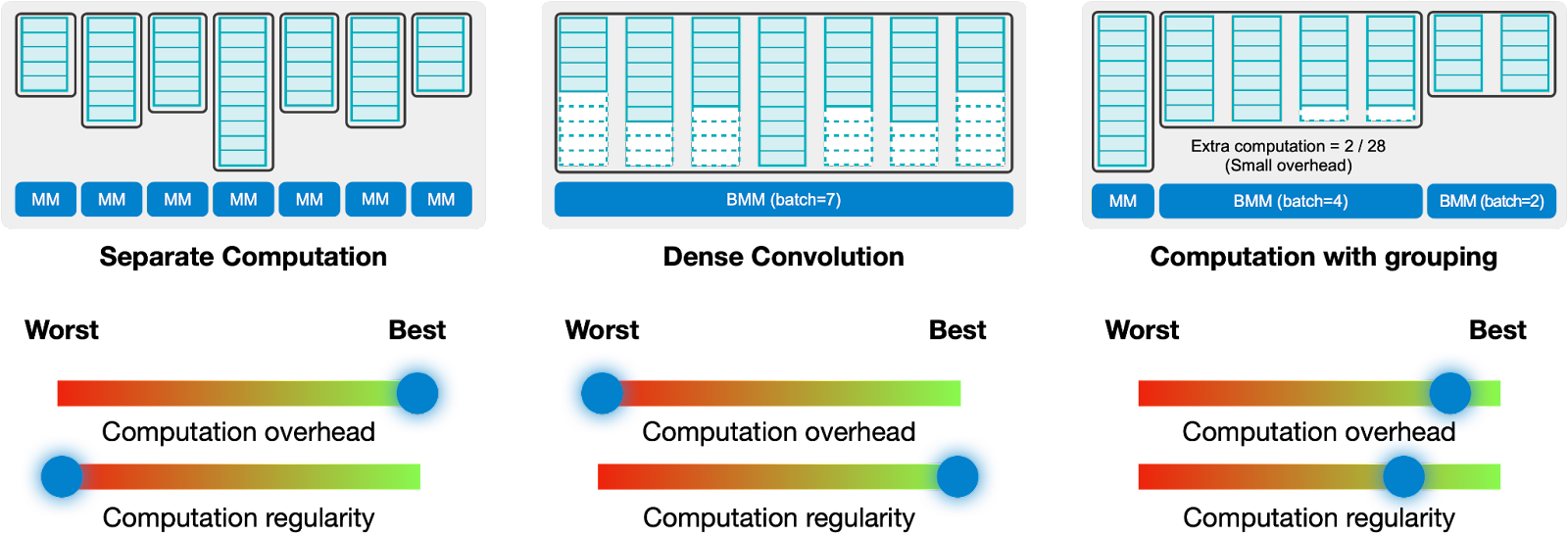
Existing libraries implement sparse convolution using a weight-stationary dataflow. This approach processes computations for different weights separately, resulting in low device utilization due to irregular computation patterns. On the other hand, padding the computations for different weights to the same size (i.e., dense convolution) improves computation regularity but introduces significant overhead.

We employ an adaptive grouping approach, which dynamically batches weight computations at runtime. Our findings reveal the existence of an optimal equilibrium between computational regularity and overhead. Notably, an input-adaptive strategy consistently outperforms a fixed strategy.
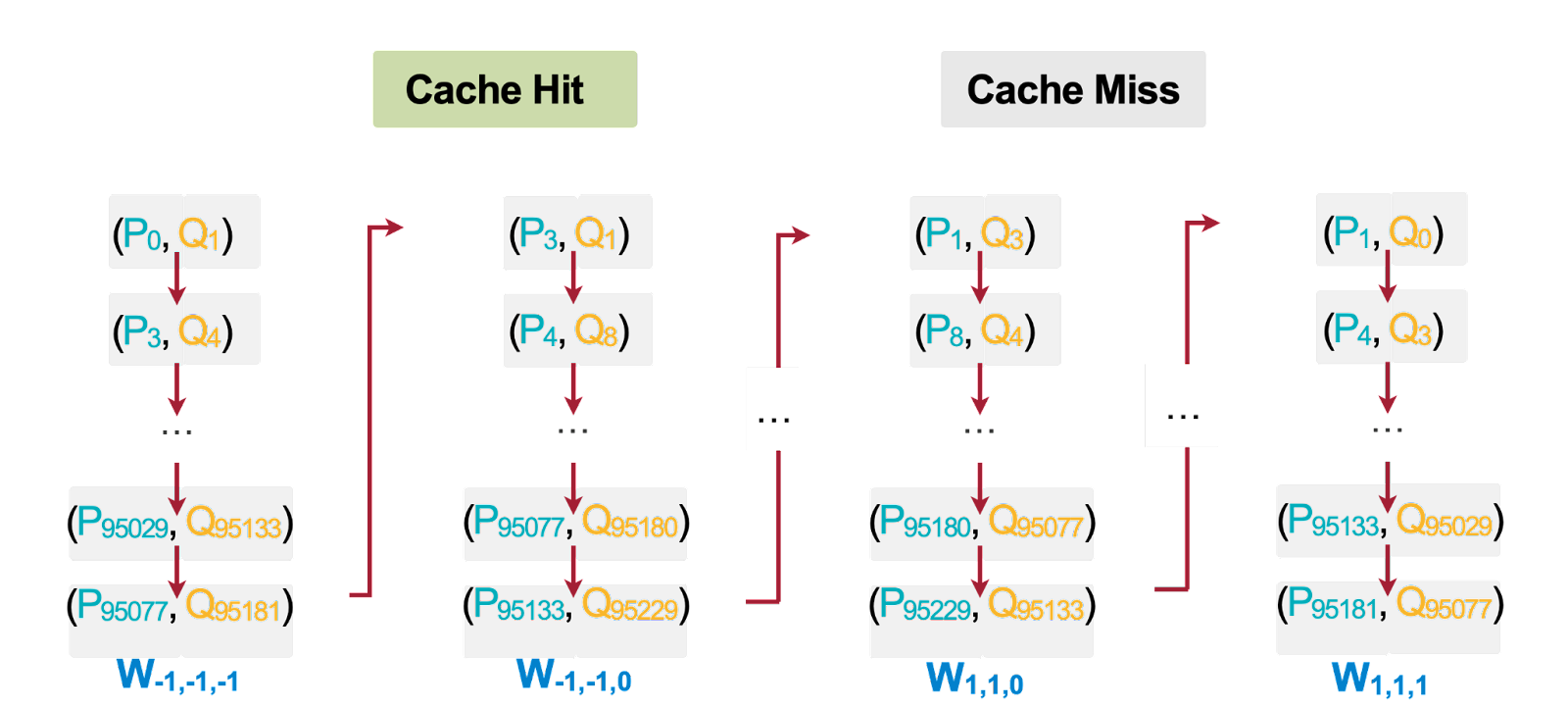
We discovered that current sparse convolution implementations exhibit notably inefficient cache utilization. Nearly every memory access results in a cache miss due to the inherent uniqueness of input-output mappings for each weight.

Drawing inspiration from a straightforward insight that prioritizing input/output stationary access optimizes cache utilization in input/output operations, we introduce a novel approach to reordering memory access in weight-stationary sparse convolutions. This helps reduce data movement time by up to 1.36x.
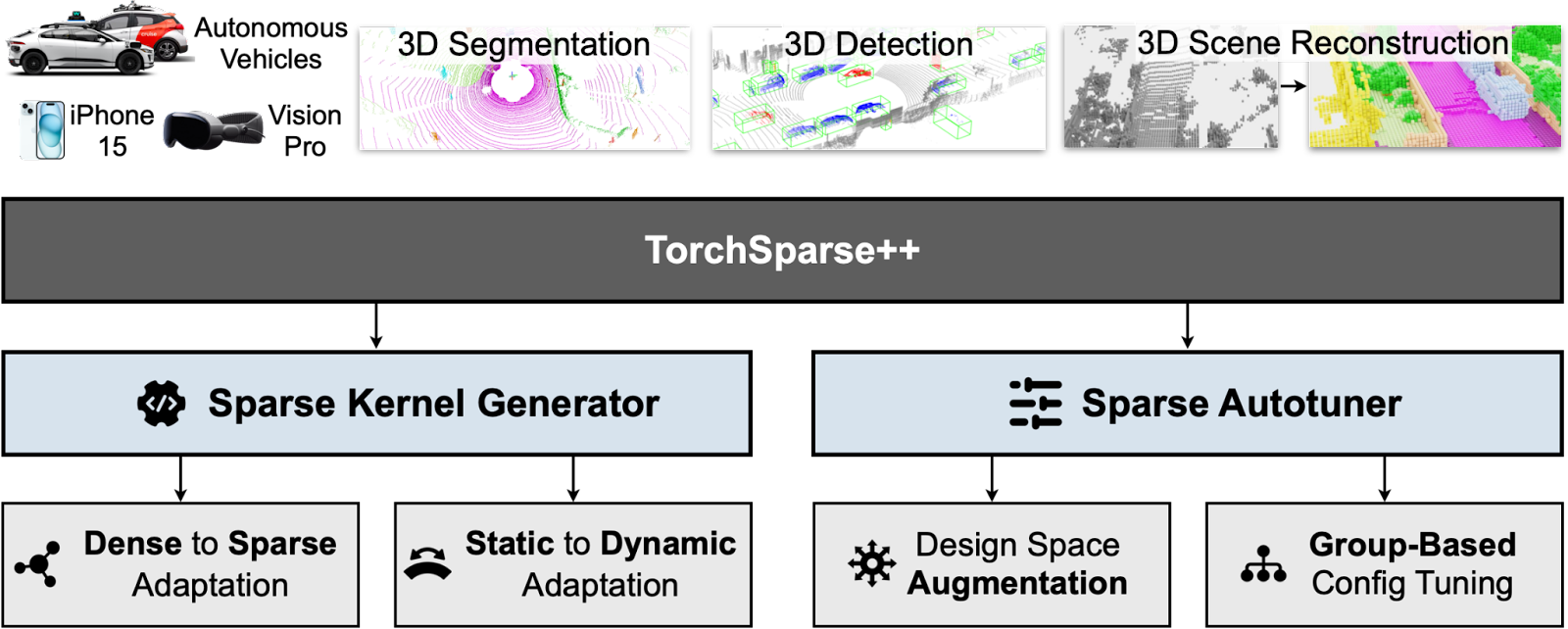
In TorchSparse++, we enhance the efficiency of sparse convolutions by implementing a pipelining approach, effectively overlapping computation with memory access. To accomplish this, we have introduced two innovative components: the sparse kernel generator and the sparse autotuner.

Our primary insight lies in recognizing that pipelined sparse convolution kernels deviate from conventional dense GEMM kernels by just a single pointer. This revelation empowers us to efficiently generate sparse convolution kernels using established tensor compilers, all while incurring minimal engineering overhead.

Our study reveals a similar trade-off between computation redundancy and computation regularity in the design of pipelined sparse convolution kernels. Devices with lower peak computational throughput tend to favor dataflows that exhibit reduced computation redundancy. Thus, it is advantageous to reduce computation overhead by partitioning the computation into more segments. In contrast, high-end devices prioritize the minimization of runtime for operations that are exclusively executed on the slower CUDA cores. Consequently, a dataflow configuration that optimizes computation regularity is the preferred choice for such devices.

We further design a group-based autotuner to encourage execution configurations that minimize mapping overhead.
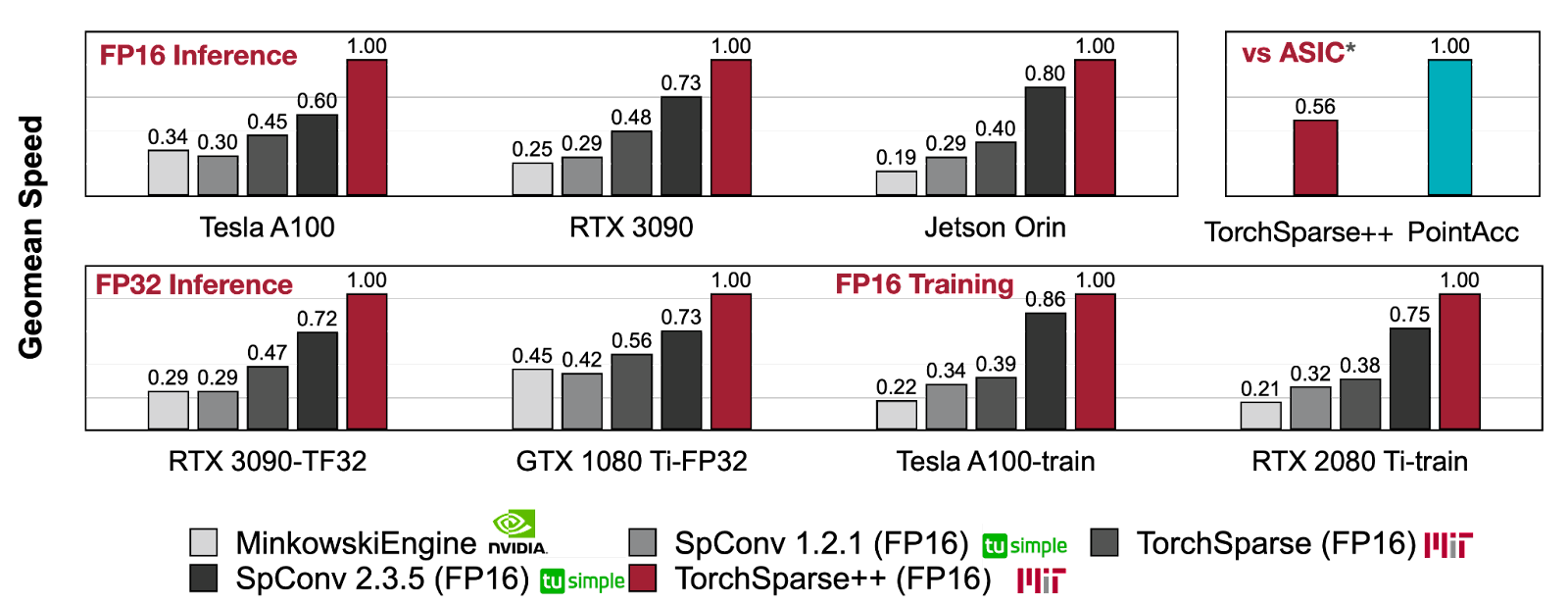
TorchSparse++ achieves up to 1.7x inference speedup and 1.3x training speedup compared with SpConv v2, the previous state-of-the-art system for the sparse convolution operator. It also compares favorably with PointAcc, the ASIC accelerator for point clouds designed by our group in MICRO 2021.
@inproceedings{tang2022torchsparse,
title={TorchSparse: Efficient Point Cloud Inference Engine},
author={Tang, Haotian and Liu, Zhijian and Li, Xiuyu and Lin, Yujun and Han, Song},
booktitle={Conference on Machine Learning and Systems (MLSys)},
year={2022}
}
We would like to thank Hanrui Wang and Ligeng Zhu for their feedback on the artifact evaluation. This research was supported by NSF CAREER Award #1943349, Hyundai and Ford. Zhijian Liu and Yujun Lin were partially supported by the Qualcomm Innovation Fellowship.



